On-Page SEO is where the heart is..

Off-Page SEO news this fine day!
Technical SEO news this fine day!
Off-Page SEO news this fine day!
Robots.txt is a file that contains instructions on how to crawl a website. It is also known as robots exclusion protocol, and this standard is used by sites to tell the bots which part of their website needs indexing. Also, you can specify which areas you don’t want to get processed by these crawlers; such areas contain duplicate content or are under development. Bots like malware detectors, email harvesters don’t follow this standard and will scan for weaknesses in your securities, and there is a considerable probability that they will begin examining your site from the areas you don’t want to be indexed.
A complete Robots.txt file contains “User-agent,” and below it, you can write other directives like “Allow,” “Disallow,” “Crawl-Delay” etc. if written manually it might take a lot of time, and you can enter multiple lines of commands in one file. If you want to exclude a page, you will need to write “Disallow: the link you don’t want the bots to visit” same goes for the allowing attribute. If you think that’s all there is in the robots.txt file then it isn’t easy, one wrong line can exclude your page from indexation queue. So, it is better to leave the task to the pros, let our Robots.txt generator take care of the file for you.
Do you know this small file is a way to unlock better rank for your website?
The first file search engine bots look at is the robot’s txt file, if it is not found, then there is a massive chance that crawlers won’t index all the pages of your site. This tiny file can be altered later when you add more pages with the help of little instructions but make sure that you don’t add the main page in the disallow directive.Google runs on a crawl budget; this budget is based on a crawl limit. The crawl limit is the number of time crawlers will spend on a website, but if Google finds out that crawling your site is shaking the user experience, then it will crawl the site slower. This slower means that every time Google sends spider, it will only check a few pages of your site and your most recent post will take time to get indexed. To remove this restriction, your website needs to have a sitemap and a robots.txt file. These files will speed up the crawling process by telling them which links of your site needs more attention.
As every bot has crawl quote for a website, this makes it necessary to have a Best robot file for a wordpress website as well. The reason is it contains a lot of pages which doesn’t need indexing you can even generate a WP robots txt file with our tools. Also, if you don’t have a robotics txt file, crawlers will still index your website, if it’s a blog and the site doesn’t have a lot of pages then it isn’t necessary to have one.
If you are creating the file manually, then you need to be aware of the guidelines used in the file. You can even modify the file later after learning how they work.
A sitemap is vital for all the websites as it contains useful information for search engines. A sitemap tells bots how often you update your website what kind of content your site provides. Its primary motive is to notify the search engines of all the pages your site has that needs to be crawled whereas robotics txt file is for crawlers. It tells crawlers which page to crawl and which not to. A sitemap is necessary in order to get your site indexed whereas robot’s txt is not (if you don’t have pages that don’t need to be indexed).
Robots txt file is easy to make but people who aren’t aware of how to, they need to follow the following instructions to save time.


|
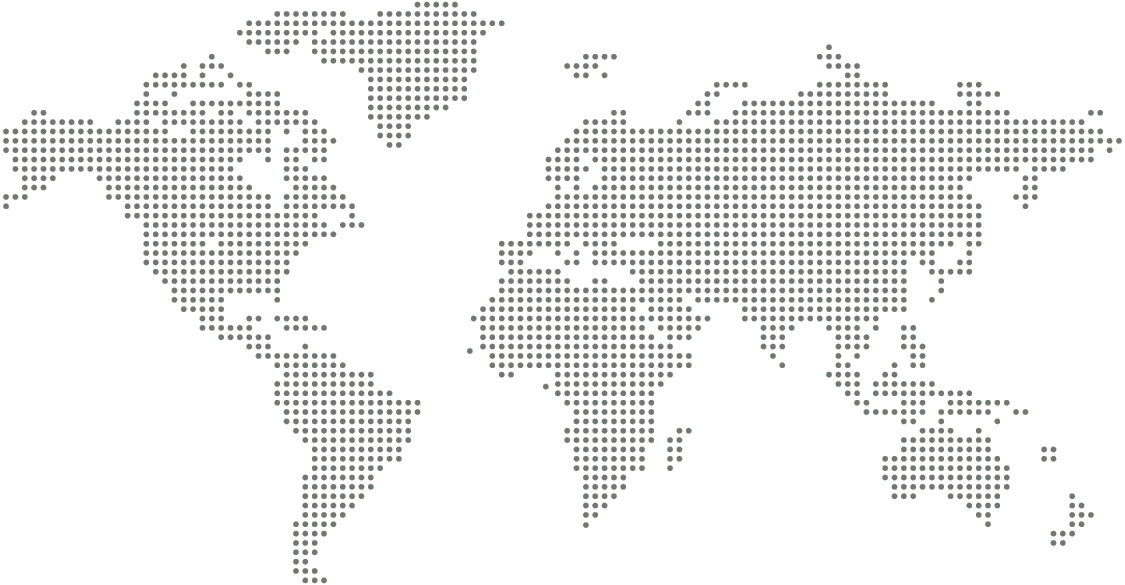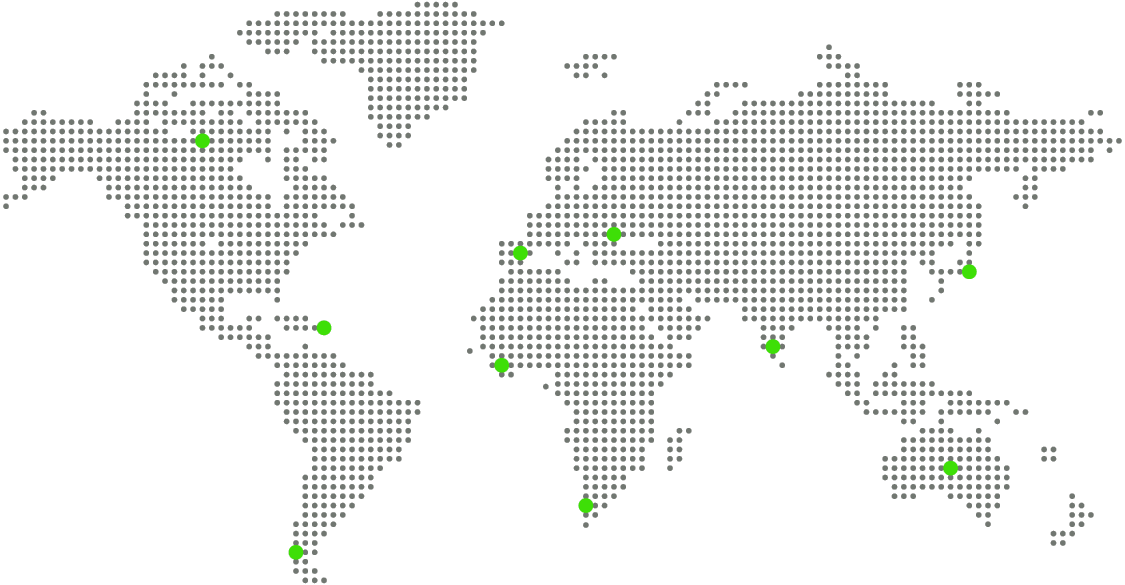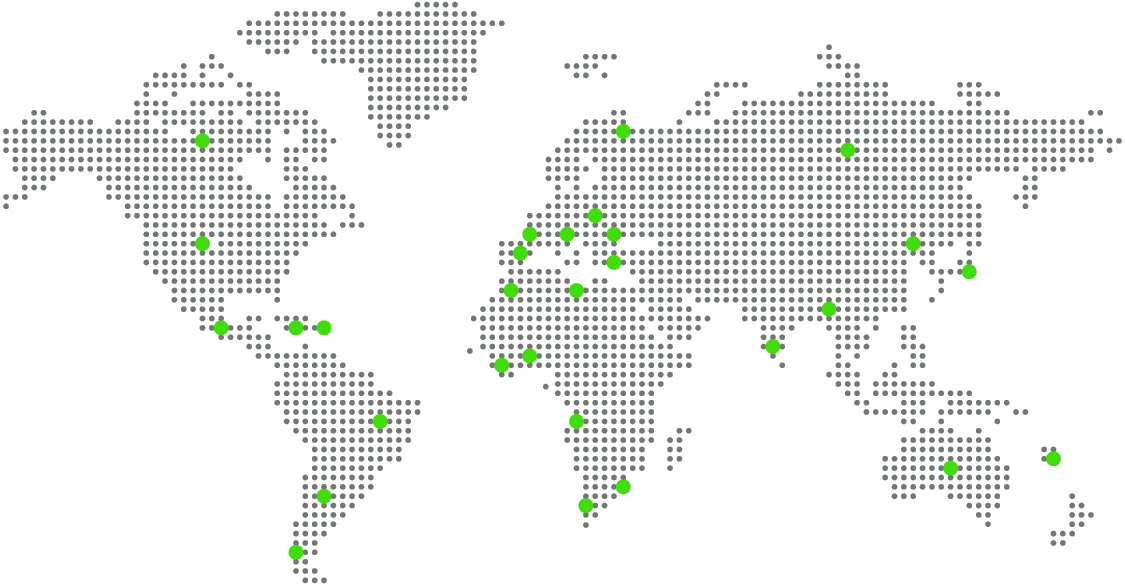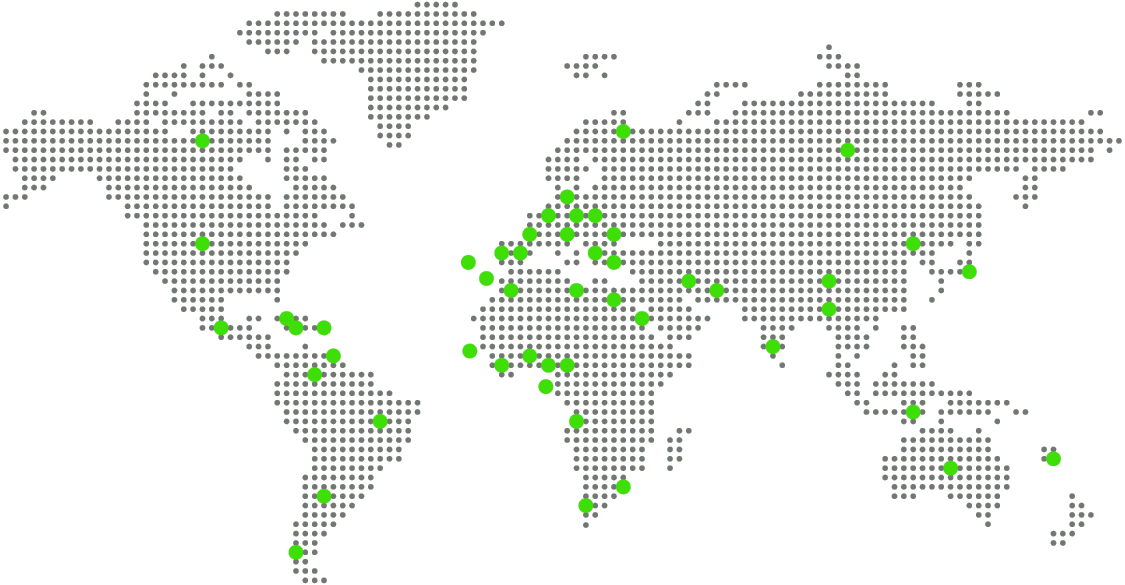
67,972 عدد أدوات السيو المستخدمة الأسبوع الماضي ▲14.26% |
|||||
|
|
المملكة المتحدة | |||||||||||||||| | ▲ | 64.11% | 9.5K |
|
|
الولايات المتحدة | |||||||||||||||| | ▼ | 14.53% | 9.1K |
|
|
السعودية | |||||||||||||||| | ▲ | 9.67% | 8.7K |
|
|
المغرب | |||||||||||||||| | ▲ | 8.34% | 7.8K |
|
|
مصر | |||||||||||||||| | ▼ | 14.88% | 6.6K |
|
|
روسيا; | |||||||||||||||| | ▲ | 92.38% | 6.2K |
|
|
الشيلي | |||||||||||||||| | ▲ | 88.64% | 5.3K |
|
|
ألمانيا | |||||||||||||||| | ▲ | 83.40% | 5.1K |
|
|
إيطاليا | |||||||||||||||| | ▲ | 64.19% | 4.9K |
|
|
البرتغال | |||||||||||||||| | ▲ | 24.33% | 4.7K |
|
11 - 20
|

آراء و ملاحظات العملاء



إحصائيات
الاشتراك في النشرة البريدية
|
. |
|
||||||||||||||||||||||||||||||||||||||||||||||||| |
||
|
كما شوهد على. |
||
|
|






